Speech Recognition with Python & CMU Sphinx

Introduction
Hi, I am Masuyama, a software engineer from WESEEK, Inc. in Japan.
In this blog, I will explain the simple way to build up speech recognition using Python and CMU Sphinx.
Source code
The working code can be found at https://github.com/hakumizuki/python_sphinx_sample.
The explanation is based on this repository, so please git clone https://github.com/hakumizuki/python_sphinx_sample if you want actually to run the code on your hand.
In the explanation, we will use devcontainer, but if you want to use external devices such as microphones, it may be easier to use an actual device rather than a container.
SpeechRecognition Library
To work with CMU Sphinx in Python, we use the SpeechRecognition library, which is responsible for the various speech recognition APIs.
CMU Sphinx is an OSS speech recognition tool that, unlike the Google Cloud Speech API, works completely offline and does not require internet access. It can recognize speech in any language by providing a language model. For more information, click here.
If you want to try other methods, please refer to this page.
Development Environment Building
- Install Docker
- Install VSCode
$ git clone https://github.com/hakumizuki/python_sphinx_sample$ cd ./python_sphinx_sample$ code .- Press [Ctrl+P or Command+P], type “Reopen in container” and click on the suggestion that comes up
Now the devcontainer has been started and the environment has been built. Let’s look at the program.
Program Description
The main library used is SpeechRecognition, a Python library for speech recognition.
Constants such as file paths are written in constants.py, and the speech recognition program is written in recognize.py.

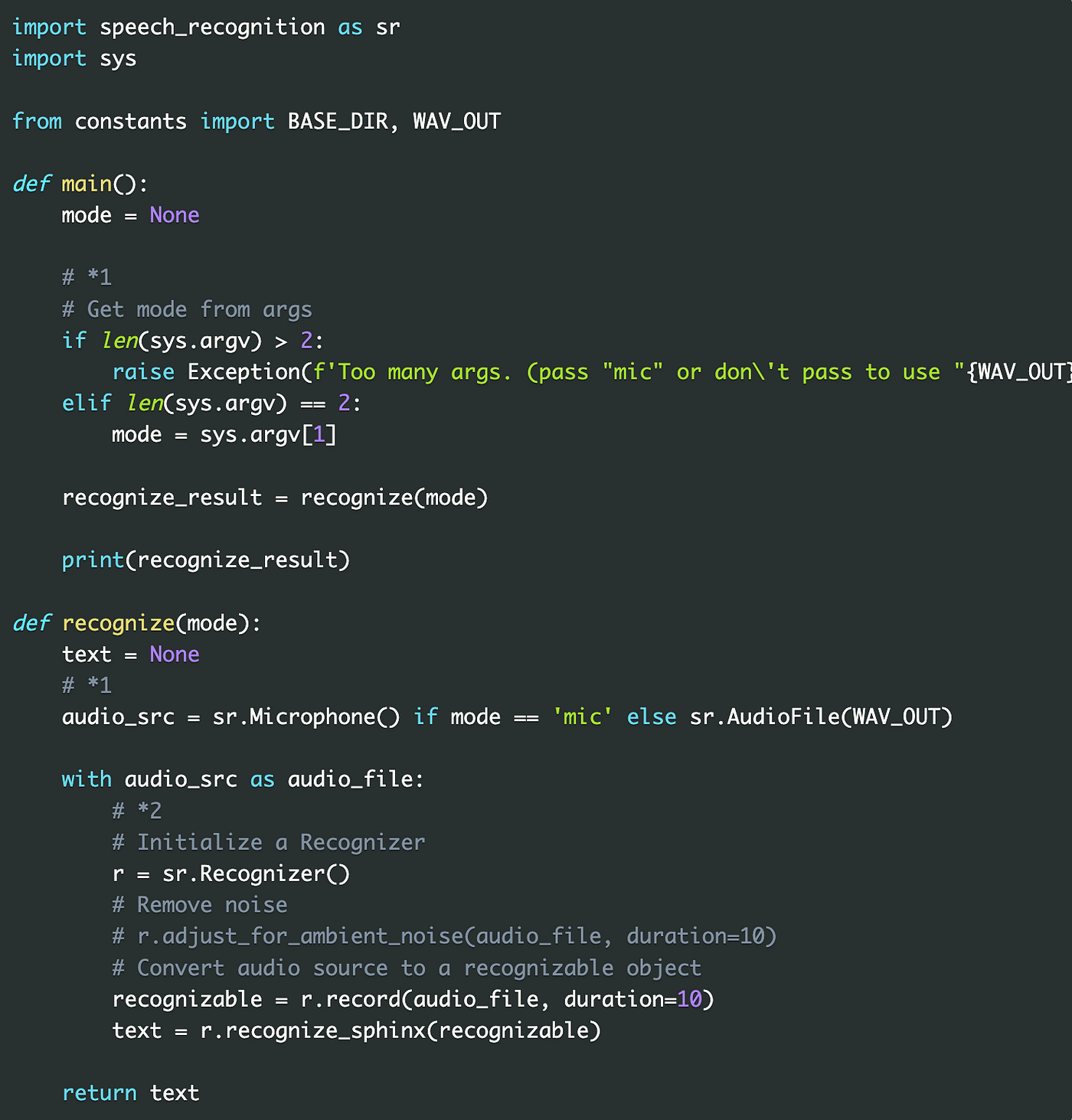
*1
python recognize.py<mode> is assumed to be used, passing micas mode will use the audio coming in from the microphone as the audio source, and not passing anything will use the audio file in WAV_OUT in constants.py as the audio source.
About microphones, please refer here.
- Running scripts outside of containers
- Set up the microphone for use on the container, referring to this article and others.
*2
- Create Recognizer instance
- Generate a speech recognition object from the audio file in the record method
- Execute the recognize_sphinx method with the object for speech recognition to perform speech recognition
Run Program
This time, I would like to create an audio file with speech.py in the repository and have it recognized. speech.py takes an English string and converts it into an audio file.
$ mkdir ./audios→ Same hierarchy as src$ python speech.py “apple banana”→ You can change to any English you like.$ python recognize.py
If the following codes are displayed, your programming is successful.

About Us💡
In addition, we want to introduce a little more about GROWI, an open software developed by WESEEK, Inc.
GROWI is a wiki service with features-rich support for efficient information storage within the company. It also boasts high security and various authentication methods are available to simplify authentication management, including LDAP/OAuth/SAML.
GROWI originated in Japan and GROWI OSS is FREE for anyone to download and use in English.
For more information, go to GROWI.org to learn more about us. You can also follow our Facebook to see updates about our service.